Spring 循环依赖
如何解决
为什么要使用三级缓存
如果只保留二级缓存行不行
BeanFacotryPostProcessor
BeanPostProcessor
BeanDefinition -> BeanFacotryPostProcessor
-> BeanFactory
-> Init Bean -> BeanPostProcessor (before) -> Init Method -> BeanPostProcessor -- after -> context.getBean()
区别 FactoryBean:产生特殊对象
Spring 在整个创建过程中,如果想在不同阶段做不同的事情怎么处理?
观察者模式
AbstractApplicationContext refresh()
refreshBeanFactory
Int multicaster
finishBeanFactoryInitialization(beanFactory)
实例化:开辟内存
初始化:初始值
DefaultListableBeanFactory
getBean(beanName)
DefaultSingltonBeanRegistry 包含三级缓存
singletonObjects; //一级缓存
singletonFactories; //三级缓存
earlySingletonObjects; //二级缓存
每次获取bean对象的时候先从以及缓存中获取值
doCreateBean
createBeanInstance 通过reflection实例化
// Eagerly cache singletons:
addSingletonFactory(beanName, () -> getEarlyBeanReference(..)); // 创建中(实例化,但未初始化)
populateProperty //填充属性
addPropertyValues
resolveValueIfNecessary
在刚刚开始我们创建对象的时候有一个循环
在正常情况下,先创造A,再创建B
但是有循环依赖的时候,在创建A的时候就把B创建了
执行 Anonymous inner class,找到创建中的A
给B中的a赋值
创建B对象目的:是再给A对象填充属性的时候发现需要B对象,所以顺带创建了B对象
一级:完整对象,(实例化+初始化都完成)
二级:创建中的对象,实例化完成,但未初始化
三级:实例化完成,但未初始化,获取 Anonymous inner class
3级用来保存获取bean的方法,方法内可以递归调用bean的创建
BeanPostProcessor
AbstractAutoProxyCreator
createProxy
如果在A上配置AOP,是否需要生成一个proxy对象?
exposedObject = ...getEarlyBeanReference(...)



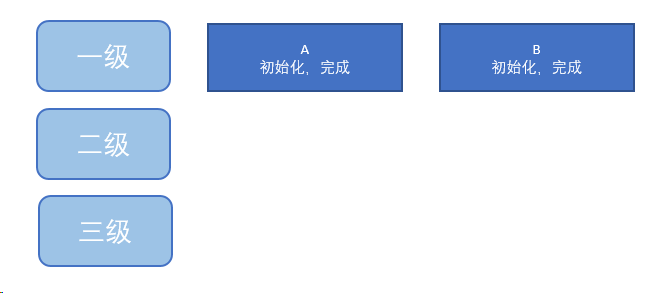
我们需要三级缓存:妮所需要的类有可能是简单对象(实例化,初始化),也可能是需要进行代理的代理对象,当我向三级缓存中放置 Anonymous inner class 的时候,可以在获取的时候决定到底是简单对象,还是代理对象
二级放的是object,三级放的是 object factory

不管在什么时候需要对象,都是在需要的时候通过 Anonymous inner class 来生成,而不是提前放治好了一个对象
