HTTP 协议 and HTTP/1.x 的缺陷
连接无法复用
连接无法复用会导致每次请求都经历三次握手和慢启动。三次握手在高延迟的场景下影响较明显,慢启动则对大量小文件请求影响较大(没有达到最大窗口请求就被终止)。
HTTP/1.0 传输数据时,每次都需要重新建立连接,增加延迟。
HTTP/1.1 虽然加入 keep-alive 可以复用一部分连接,但域名分片等情况下仍然需要建立多个 connection,耗费资源,给服务器带来性能压力。
Head-Of-Line Blocking(HOLB)
导致带宽无法被充分利用,以及后续健康请求被阻塞。HOLB是指一系列包(package)因为第一个包被阻塞;当页面中需要请求很多资源的时候,HOLB(队头阻塞)会导致在达到最大请求数量时,剩余的资源需要等待其他资源请求完成后才能发起请求。
HTTP 1.0:下个请求必须在前一个请求返回后才能发出,request-response对按序发生。显然,如果某个请求长时间没有返回,那么接下来的请求就全部阻塞了。
HTTP 1.1:尝试使用 pipeling 来解决,即浏览器可以一次性发出多个请求(同个域名,同一条 TCP 链接)。但 pipeling 要求返回是按序的,那么前一个请求如果很耗时(比如处理大图片),那么后面的请求即使服务器已经处理完,仍会等待前面的请求处理完才开始按序返回。所以,pipeling 只部分解决了 HOLB。
协议开销大:无状态特性 – 带来巨大的 HTTP 头部
HTTP1.x 在使用时,header 里携带的内容过大,在一定程度上增加了传输的成本,并且每次请求 header 基本不怎么变化,尤其在移动端增加用户流量。
安全因素
HTTP1.x 在传输数据时,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份,这在一定程度上无法保证数据的安全性
HTTP/1.1 无法为重要的资源指定优先级
每个 HTTP 请求都是一视同仁。
SPDY 协议 and HTTP/2
HTTP/2 基于 SPDY3,专注于性能

最大的一个目标是在用户和网站间只用一个连接(connection)
HTTP/2 新特性
二进制传输
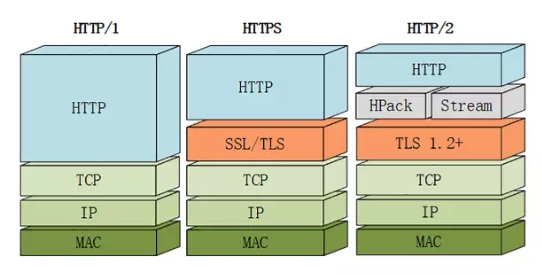
HTTP/2 采用二进制格式传输数据,而非 HTTP 1.x 的文本格式,二进制协议解析起来更高效。
HTTP/1 的请求和响应报文,都是由起始行,首部和实体正文(可选)组成,各部分之间以文本换行符分隔。
HTTP/2 将请求和响应数据分割为更小的帧,并且它们采用二进制编码。
E.g. Headers frame, Data frame
多路复用 Multiplexing
在 HTTP/1.1 中,如果客户端想发送多个并行的请求,那么必须使用多个 TCP 连接。
HTTP/2 中,所有的请求和响应都在同一个 TCP 连接上发送:客户端和服务器把 HTTP 消息分解成多个帧,然后乱序发送,最后在另一端再根据流 ID 重新组合起来。
Stream:流是连接中的一个虚拟信道,可以承载双向的消息;每个流都有一个唯一的整数标识符(1、2…N);
消息:是指逻辑上的 HTTP 消息,比如请求、响应等,由一或多个帧组成。
Frame:HTTP 2.0 通信的最小单位,每个帧包含帧首部,至少也会标识出当前帧所属的流,承载着特定类型的数据,如 HTTP 首部、负荷,等等
在 HTTP/2 中,每个请求都可以带一个 31bit 的优先值,0 表示最高优先级, 数值越大优先级越低。有了这个优先值,客户端和服务器就可以在处理不同的流时采取不同的策略,以最优的方式发送流、消息和帧。
流量控制
每一跳,而不是端对端
Header 压缩
在 HTTP/1 中,我们使用文本的形式传输 header,在 header 携带 cookie 的情况下,可能每次都需要重复传输几百到几千的字节。
为了减少这块的资源消耗并提升性能, HTTP/2 对这些 Header 采取了压缩策略:
HTTP/2 在客户端和服务器端使用“首部表”来跟踪和存储之前发送的键-值对,对于相同的数据,不再通过每次请求和响应发送;
首部表在 HTTP/2 的连接存续期内始终存在,由客户端和服务器共同渐进地更新;
每个新的首部键-值对要么被追加到当前表的末尾,要么替换表中之前的值
Server Push
Server Push 即服务端能通过 push 的方式将客户端需要的内容预先推送过去,
也叫“cache push”。
某些资源客户端是一定会请求的
服务端可以主动推送,客户端也有权利选择是否接收。
如果服务端推送的资源已经被浏览器缓存过,浏览器可以通过发送 RST_STREAM 帧来拒收。
主动推送也遵守同源策略,换句话说,服务器不能随便将第三方资源推送给客户端,而必须是经过双方确认才行。
HTTP/2 的缺点
HTTP/2 仍然实建立在 TCP 协议上的。
TCP 和 TCP+TLS 建立连接的延时
TCP 的队头阻塞并没有彻底解决,而且当出现了丢包时,HTTP/2 的表现反倒不如 HTTP/1 了(TCP“丢包重传”机制,整个 TCP 都要开始等待重传,也就导致了后面的所有数据都被阻塞了)。
HTTP 3.0

0-RTT
通过使用类似 TCP 快速打开的技术,缓存当前会话的上下文,在下次恢复会话的时候,只需要将之前的缓存传递给服务端验证通过就可以进行传输了。0RTT 建连可以说是 QUIC 相比 HTTP2 最大的性能优势。
传输层 0RTT 就能建立连接。
加密层 0RTT 就能建立加密连接。
Multiplexing 依旧
同 HTTP2.0 一样,同一条 QUIC 连接上可以创建多个 stream,来发送多个 HTTP 请求,但是,QUIC 是基于 UDP 的,一个连接上的多个 stream 之间没有依赖。比如下图中 stream2 丢了一个 UDP 包,不会影响后面跟着 Stream3 和 Stream4,不存在 TCP 队头阻塞。虽然 stream2 的那个包需要重新传,但是 stream3、stream4 的包无需等待,就可以发给用户。
加密
所有报文 Header 都是经过认证的,报文 Body 都是经过加密的。
向前纠错机制
QUIC 协议有一个非常独特的特性,称为向前纠错 (Forward Error Correction,FEC),每个数据包除了它本身的内容之外,还包括了部分其他数据包的数据,因此少量的丢包可以通过其他包的冗余数据直接组装而无需重传。向前纠错牺牲了每个数据包可以发送数据的上限,但是减少了因为丢包导致的数据重传,因为数据重传将会消耗更多的时间(包括确认数据包丢失、请求重传、等待新数据包等步骤的时间消耗)
假如说这次我要发送三个包,那么协议会算出这三个包的异或值并单独发出一个校验包,也就是总共发出了四个包。当出现其中的非校验包丢包的情况时,可以通过另外三个包计算出丢失的数据包的内容。当然这种技术只能使用在丢失一个包的情况下,如果出现丢失多个包就不能使用纠错机制了,只能使用重传的方式了。